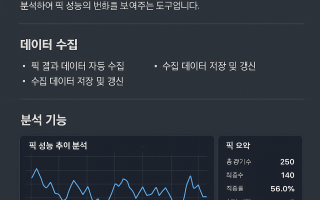
스포츠 예측모델 학습 데이터 수집 가이드
페이지 정보

본문

스포츠 예측모델 학습 데이터 수집 가이드는 축구, 농구, 야구 등 다양한 종목의 예측 모델을 구축하기 위해 필요한 데이터를 효과적으로 수집하고 정제하는 과정을 총망라한 완전한 로드맵입니다. 특히 머신러닝과 AI 기반의 예측 시스템을 학습시키기 위해 어떤 데이터를 어떤 구조로 수집하고, 어떻게 전처리하여, 어떤 포맷으로 저장할지에 대해 실전 예시와 코드 중심으로 설명합니다.
이 가이드는 초보 분석가부터 현업 데이터 과학자까지 모두에게 유용한 실전 중심 지침서로, 스포츠 데이터의 활용 가능성을 최대화하고, 예측 모델의 정확도를 높이는 데 중점을 둡니다.
1. 머신러닝 예측 모델에 유용한 데이터 구조
머신러닝 기반의 스포츠 예측 모델이 잘 작동하기 위해서는 양질의 구조화된 데이터가 핵심입니다. 아래는 예측에 특히 유용한 범주와 항목들을 정리한 것입니다.
범주 예시 항목
기본 경기 정보 경기일, 리그명, 시즌, 홈/원정, 경기장, 관중 수 등
결과 변수 홈팀 승/무/패, 최종 스코어, 골차, 핸디캡 적용 결과
경기 통계 슈팅 수, 유효 슛, 점유율, 파울, 세이브, 코너킥 등
선수 통계 출장 선수 목록, 득점자, 패스 성공률, 태클 수, 부상 여부 등
팀 성향 홈/원정 승률, 최근 5경기 득실점, 무실점 경기 횟수 등
외부 변수 날씨, 경기 요일/시간, 이동 거리, 휴식일 수 등
베팅 요소 초기/최종 배당률, 핸디캡 수치, 베팅 금액 추이, 베팅량 분포 등
이처럼 다양한 변수는 모델이 경기의 맥락과 복잡한 영향을 더 잘 이해하도록 도와주며, 궁극적으로 예측 성능 향상에 크게 기여합니다. 스포츠 예측모델 학습 데이터 수집 가이드는 이처럼 다양한 범주를 실제 데이터로 전환하는 방법까지 제시합니다.
2. 추천 데이터 소스 및 수집 방법
고품질 데이터는 좋은 예측 모델의 전제조건입니다. 스포츠 예측모델 학습 데이터 수집 가이드에서는 다음과 같은 데이터 소스를 추천합니다.
Football-Data.co.uk
: 유럽 주요 리그의 경기 결과와 배당률 데이터를 무료 CSV로 제공.
TheSportsDB
: 다종목 API 서비스 제공. 경기 일정, 결과, 팀 정보, 배당 데이터 포함.
API‑Football (RapidAPI)
: REST API 방식으로 경기 정보, 팀 통계, 베팅 지표를 유료로 제공.
FBref.com
: 축구 선수별 고급 지표(xG, 포메이션 등) 제공. BeautifulSoup + pandas로 크롤링 가능.
SofaScore / Flashscore
: 실시간 경기 데이터. Selenium, Requests 등 활용해 자동화 가능.
이처럼 다양한 데이터 소스를 통해 단일 경기 데이터부터 선수, 베팅 정보까지 확장 가능한 구조를 갖출 수 있습니다.
3. 주요 수집 코드 예제
FBref 크롤링 예시
python
복사
편집
import requests
from bs4 import BeautifulSoup
import pandas as pd
url = "https://fbref.com/en/comps/9/schedule/Premier-League-Scores-and-Fixtures"
res = requests.get(url, headers={"User-Agent":"Mozilla/5.0"})
soup = BeautifulSoup(res.text, "html.parser")
rows = soup.select("table#sched_ks_3232_1 tr")[1:]
data=
for r in rows:
cols = r.find_all("td")
if cols:
data.append([cols[0].text.strip(), cols[4].text, cols[6].text, cols[8].text])
df = pd.DataFrame(data, columns=["날짜","홈","원정","스코어"])
df.to_csv("epl_matches.csv", index=False)
TheSportsDB API 활용 예시
python
복사
편집
import thesportsdb
api = thesportsdb
events = api.events.leagueSeasonEvents("4328","2023-2024")
matches=[{"date":e["dateEvent"], "home": e["strHomeTeam"], ...} for e in events]
pd.DataFrame(matches).to_csv("tsdb_epl.csv", index=False)
스포츠 예측모델 학습 데이터 수집 가이드에서는 위처럼 API, 크롤링 등 다양한 방식으로 데이터를 수집하고 저장하는 방식을 권장합니다.
4. 전처리 핵심 작업
데이터 수집이 끝났다면, 다음은 머신러닝 모델 학습을 위한 전처리 단계입니다.
결측값 처리: 스코어, 선수 기록 등의 누락은 평균 대체, 제거 등 적용
범주형 인코딩: 팀명, 리그명 등은 One-Hot 또는 Label Encoding
정규화: 슈팅 수, 관중 수, 배당 등은 MinMax 또는 StandardScaler로 정규화
불균형 클래스 처리: SMOTE, ADASYN 등을 통해 무승부 등 소수 클래스 보완
로그 변환: 베팅 배당률, 관중 수처럼 분포 왜곡이 큰 변수는 log 스케일링 적용
이 과정을 통해 머신러닝 알고리즘이 최적의 성능을 발휘할 수 있는 학습 환경을 조성할 수 있습니다.
5. 추천 Feature 예시 (축구 기준)
Feature명 설명
home_win_rate 홈팀 최근 5경기 승률
away_goal_concede_avg 원정팀 평균 실점
possession_diff 홈/원정 점유율 차이
odds_home_win 홈팀 초기 배당률
goal_diff_last3 최근 3경기의 득실점 차
rest_days_home 홈팀 최근 경기 이후 휴식일 수
is_derby 라이벌 매치 여부 (Yes/No)
스포츠 예측모델 학습 데이터 수집 가이드는 이처럼 실제 예측 정확도에 영향을 미치는 다양한 피처를 설계하고 모델에 반영할 수 있도록 방향을 제시합니다.
6. 자동 수집 파이프라인 구성
스케줄링: cron, schedule 패키지를 통해 매일 또는 주기적 수집
API 호출 자동화: RapidAPI, TheSportsDB API를 주기적으로 호출하여 자동 저장
크롤링 파이프라인: Selenium 또는 BeautifulSoup을 사용한 자동 크롤러 배치
Google Sheets 연동: API를 통해 실시간 시각화와 데이터 공유 연동 가능
7. 저장 포맷 추천
포맷 용도
.csv 초기 데이터 분석 및 Pandas 처리에 적합
.json 웹 기반 API 결과, 비정형 데이터 저장에 적합
.parquet 대용량 데이터의 빠른 저장 및 로딩에 유리
DB 저장 PostgreSQL, SQLite, MongoDB 등과 연동하여 구조화된 관리 가능
8. 다음 단계 – 머신러닝 모델 예측
수집 및 전처리 완료된 데이터를 불러오기
scikit-learn, XGBoost, LightGBM 등으로 모델 학습
정확도, F1, AUC, 혼동 행렬 등으로 평가
예측 결과를 실제 배당과 비교하여 Value Bet 판단
스포츠 예측모델 학습 데이터 수집 가이드는 단순 수집을 넘어 머신러닝 모델 적용까지 완성도 높은 파이프라인 설계의 전 단계를 다룹니다.
요약
스포츠 예측모델 학습 데이터 수집 가이드는 머신러닝 기반 예측의 출발점인 데이터 수집을 정밀하고 체계적으로 구성하는 데 중점을 둡니다.
다양한 소스(API, 크롤링), 고급 전처리, 자동화 스케줄링, 저장 포맷까지 완비된 구성입니다.
모델 성능 향상을 위해 피처 설계와 변환 기법, 실제 모델 학습까지 연결되는 실전 지침서입니다.
향후 Streamlit 대시보드, Slack 알림, AutoML 템플릿 등과 연계하면 분석 및 운영 효율을 극대화할 수 있습니다.
자주 묻는 질문 (FAQs)
Q1. 스포츠 예측에 가장 중요한 데이터는 무엇인가요?
A. 경기 결과(승/무/패), 스코어, 홈/원정 여부, 팀의 최근 성적, 배당률이 기본입니다. 여기에 점유율, 슈팅 수, 선수 출전 여부, 휴식일 등 상세 통계를 추가하면 예측 정확도가 크게 향상됩니다. 스포츠 예측모델 학습 데이터 수집 가이드는 이러한 항목을 분류별로 정리해 제공합니다.
Q2. 무료로 사용할 수 있는 고품질 데이터 소스가 있나요?
A. 네, 있습니다.
Football-Data.co.uk는 유럽 축구 리그 데이터를 CSV 형식으로 무료 제공합니다.
TheSportsDB는 다양한 종목의 경기 일정, 결과, 배당 데이터를 API로 제공합니다.
FBref는 선수 스탯과 xG 등의 고급 지표를 HTML 테이블 형태로 제공합니다.
Q3. 배당률 데이터를 예측 모델에 활용하려면 어떻게 전처리하나요?
A. 배당률은 로그 변환 또는 Reciprocal 변환(1/배당률) 방식으로 스케일 조정이 필요합니다. 또한 홈/원정/무승부 각각의 배당을 Feature로 나눠서 학습에 넣는 것이 좋습니다. 극단적인 배당 값은 예외 처리해야 합니다.
Q4. 데이터는 얼마나 많이 수집해야 하나요?
A. 최소 수천 건 이상이 바람직합니다. 일반적으로 3~5시즌(연도) 이상의 데이터가 있으면 모델이 리그 특성, 팀 흐름, 시즌별 변수에 대해 충분히 학습할 수 있습니다. 특히 비정상적인 경기(예: 코로나 시기 무관중 경기)는 별도로 구분하는 것도 좋습니다.
Q5. 크롤링이 어려운데 API만으로도 충분한가요?
A. 종목과 분석 범위에 따라 다릅니다.
TheSportsDB, API-Football 등 API는 구조화된 데이터 제공이 강점이며 학습용으로 충분히 활용 가능합니다.
하지만 일부 세부 지표(xG, 포메이션 등)는 크롤링(FBref, SofaScore 등)이 필요한 경우도 있습니다.
스포츠 예측모델 학습 데이터 수집 가이드에서는 크롤링과 API 병행을 추천합니다.
Q6. 경기 외적 요소(날씨, 휴식일 등)는 꼭 넣어야 하나요?
A. 단기 예측에서는 영향이 작을 수 있으나, 장기 분석에서는 중요할 수 있습니다.
예: 이동 거리, 휴식일 차이, 경기 요일(평일/주말), 시간대 등은 팀 컨디션과 연계되며, 특히 중립 경기나 국제 대회에서 효과가 큽니다.
Q7. 예측 모델을 구성할 때 어떤 알고리즘을 추천하나요?
A. 초기에는 다음을 추천합니다:
Logistic Regression: 기본적인 승/패 분류
Random Forest / XGBoost: 피처 해석력 + 정확도 우수
LightGBM: 속도와 성능의 균형
CatBoost: 범주형 자동 처리
고급 분석 시 시계열 예측(Pytorch LSTM, Prophet)도 고려할 수 있습니다.
Q8. 예측 정확도를 어떻게 평가하나요?
A. 가장 일반적인 방법은 **정확도(Accuracy)**입니다. 그러나 무승부나 저확률 경기가 많은 경우에는
Precision / Recall
F1 Score
ROC-AUC Curve
LogLoss
같은 다양한 지표로 함께 평가하는 것이 중요합니다.
#스포츠예측모델 #데이터수집가이드 #머신러닝스포츠 #스포츠데이터 #축구예측 #스포츠크롤링 #API축구데이터 #배당분석 #자동수집 #전처리코드
이 가이드는 초보 분석가부터 현업 데이터 과학자까지 모두에게 유용한 실전 중심 지침서로, 스포츠 데이터의 활용 가능성을 최대화하고, 예측 모델의 정확도를 높이는 데 중점을 둡니다.
1. 머신러닝 예측 모델에 유용한 데이터 구조
머신러닝 기반의 스포츠 예측 모델이 잘 작동하기 위해서는 양질의 구조화된 데이터가 핵심입니다. 아래는 예측에 특히 유용한 범주와 항목들을 정리한 것입니다.
범주 예시 항목
기본 경기 정보 경기일, 리그명, 시즌, 홈/원정, 경기장, 관중 수 등
결과 변수 홈팀 승/무/패, 최종 스코어, 골차, 핸디캡 적용 결과
경기 통계 슈팅 수, 유효 슛, 점유율, 파울, 세이브, 코너킥 등
선수 통계 출장 선수 목록, 득점자, 패스 성공률, 태클 수, 부상 여부 등
팀 성향 홈/원정 승률, 최근 5경기 득실점, 무실점 경기 횟수 등
외부 변수 날씨, 경기 요일/시간, 이동 거리, 휴식일 수 등
베팅 요소 초기/최종 배당률, 핸디캡 수치, 베팅 금액 추이, 베팅량 분포 등
이처럼 다양한 변수는 모델이 경기의 맥락과 복잡한 영향을 더 잘 이해하도록 도와주며, 궁극적으로 예측 성능 향상에 크게 기여합니다. 스포츠 예측모델 학습 데이터 수집 가이드는 이처럼 다양한 범주를 실제 데이터로 전환하는 방법까지 제시합니다.
2. 추천 데이터 소스 및 수집 방법
고품질 데이터는 좋은 예측 모델의 전제조건입니다. 스포츠 예측모델 학습 데이터 수집 가이드에서는 다음과 같은 데이터 소스를 추천합니다.
Football-Data.co.uk
: 유럽 주요 리그의 경기 결과와 배당률 데이터를 무료 CSV로 제공.
TheSportsDB
: 다종목 API 서비스 제공. 경기 일정, 결과, 팀 정보, 배당 데이터 포함.
API‑Football (RapidAPI)
: REST API 방식으로 경기 정보, 팀 통계, 베팅 지표를 유료로 제공.
FBref.com
: 축구 선수별 고급 지표(xG, 포메이션 등) 제공. BeautifulSoup + pandas로 크롤링 가능.
SofaScore / Flashscore
: 실시간 경기 데이터. Selenium, Requests 등 활용해 자동화 가능.
이처럼 다양한 데이터 소스를 통해 단일 경기 데이터부터 선수, 베팅 정보까지 확장 가능한 구조를 갖출 수 있습니다.
3. 주요 수집 코드 예제
FBref 크롤링 예시
python
복사
편집
import requests
from bs4 import BeautifulSoup
import pandas as pd
url = "https://fbref.com/en/comps/9/schedule/Premier-League-Scores-and-Fixtures"
res = requests.get(url, headers={"User-Agent":"Mozilla/5.0"})
soup = BeautifulSoup(res.text, "html.parser")
rows = soup.select("table#sched_ks_3232_1 tr")[1:]
data=
for r in rows:
cols = r.find_all("td")
if cols:
data.append([cols[0].text.strip(), cols[4].text, cols[6].text, cols[8].text])
df = pd.DataFrame(data, columns=["날짜","홈","원정","스코어"])
df.to_csv("epl_matches.csv", index=False)
TheSportsDB API 활용 예시
python
복사
편집
import thesportsdb
api = thesportsdb
events = api.events.leagueSeasonEvents("4328","2023-2024")
matches=[{"date":e["dateEvent"], "home": e["strHomeTeam"], ...} for e in events]
pd.DataFrame(matches).to_csv("tsdb_epl.csv", index=False)
스포츠 예측모델 학습 데이터 수집 가이드에서는 위처럼 API, 크롤링 등 다양한 방식으로 데이터를 수집하고 저장하는 방식을 권장합니다.
4. 전처리 핵심 작업
데이터 수집이 끝났다면, 다음은 머신러닝 모델 학습을 위한 전처리 단계입니다.
결측값 처리: 스코어, 선수 기록 등의 누락은 평균 대체, 제거 등 적용
범주형 인코딩: 팀명, 리그명 등은 One-Hot 또는 Label Encoding
정규화: 슈팅 수, 관중 수, 배당 등은 MinMax 또는 StandardScaler로 정규화
불균형 클래스 처리: SMOTE, ADASYN 등을 통해 무승부 등 소수 클래스 보완
로그 변환: 베팅 배당률, 관중 수처럼 분포 왜곡이 큰 변수는 log 스케일링 적용
이 과정을 통해 머신러닝 알고리즘이 최적의 성능을 발휘할 수 있는 학습 환경을 조성할 수 있습니다.
5. 추천 Feature 예시 (축구 기준)
Feature명 설명
home_win_rate 홈팀 최근 5경기 승률
away_goal_concede_avg 원정팀 평균 실점
possession_diff 홈/원정 점유율 차이
odds_home_win 홈팀 초기 배당률
goal_diff_last3 최근 3경기의 득실점 차
rest_days_home 홈팀 최근 경기 이후 휴식일 수
is_derby 라이벌 매치 여부 (Yes/No)
스포츠 예측모델 학습 데이터 수집 가이드는 이처럼 실제 예측 정확도에 영향을 미치는 다양한 피처를 설계하고 모델에 반영할 수 있도록 방향을 제시합니다.
6. 자동 수집 파이프라인 구성
스케줄링: cron, schedule 패키지를 통해 매일 또는 주기적 수집
API 호출 자동화: RapidAPI, TheSportsDB API를 주기적으로 호출하여 자동 저장
크롤링 파이프라인: Selenium 또는 BeautifulSoup을 사용한 자동 크롤러 배치
Google Sheets 연동: API를 통해 실시간 시각화와 데이터 공유 연동 가능
7. 저장 포맷 추천
포맷 용도
.csv 초기 데이터 분석 및 Pandas 처리에 적합
.json 웹 기반 API 결과, 비정형 데이터 저장에 적합
.parquet 대용량 데이터의 빠른 저장 및 로딩에 유리
DB 저장 PostgreSQL, SQLite, MongoDB 등과 연동하여 구조화된 관리 가능
8. 다음 단계 – 머신러닝 모델 예측
수집 및 전처리 완료된 데이터를 불러오기
scikit-learn, XGBoost, LightGBM 등으로 모델 학습
정확도, F1, AUC, 혼동 행렬 등으로 평가
예측 결과를 실제 배당과 비교하여 Value Bet 판단
스포츠 예측모델 학습 데이터 수집 가이드는 단순 수집을 넘어 머신러닝 모델 적용까지 완성도 높은 파이프라인 설계의 전 단계를 다룹니다.
요약
스포츠 예측모델 학습 데이터 수집 가이드는 머신러닝 기반 예측의 출발점인 데이터 수집을 정밀하고 체계적으로 구성하는 데 중점을 둡니다.
다양한 소스(API, 크롤링), 고급 전처리, 자동화 스케줄링, 저장 포맷까지 완비된 구성입니다.
모델 성능 향상을 위해 피처 설계와 변환 기법, 실제 모델 학습까지 연결되는 실전 지침서입니다.
향후 Streamlit 대시보드, Slack 알림, AutoML 템플릿 등과 연계하면 분석 및 운영 효율을 극대화할 수 있습니다.
자주 묻는 질문 (FAQs)
Q1. 스포츠 예측에 가장 중요한 데이터는 무엇인가요?
A. 경기 결과(승/무/패), 스코어, 홈/원정 여부, 팀의 최근 성적, 배당률이 기본입니다. 여기에 점유율, 슈팅 수, 선수 출전 여부, 휴식일 등 상세 통계를 추가하면 예측 정확도가 크게 향상됩니다. 스포츠 예측모델 학습 데이터 수집 가이드는 이러한 항목을 분류별로 정리해 제공합니다.
Q2. 무료로 사용할 수 있는 고품질 데이터 소스가 있나요?
A. 네, 있습니다.
Football-Data.co.uk는 유럽 축구 리그 데이터를 CSV 형식으로 무료 제공합니다.
TheSportsDB는 다양한 종목의 경기 일정, 결과, 배당 데이터를 API로 제공합니다.
FBref는 선수 스탯과 xG 등의 고급 지표를 HTML 테이블 형태로 제공합니다.
Q3. 배당률 데이터를 예측 모델에 활용하려면 어떻게 전처리하나요?
A. 배당률은 로그 변환 또는 Reciprocal 변환(1/배당률) 방식으로 스케일 조정이 필요합니다. 또한 홈/원정/무승부 각각의 배당을 Feature로 나눠서 학습에 넣는 것이 좋습니다. 극단적인 배당 값은 예외 처리해야 합니다.
Q4. 데이터는 얼마나 많이 수집해야 하나요?
A. 최소 수천 건 이상이 바람직합니다. 일반적으로 3~5시즌(연도) 이상의 데이터가 있으면 모델이 리그 특성, 팀 흐름, 시즌별 변수에 대해 충분히 학습할 수 있습니다. 특히 비정상적인 경기(예: 코로나 시기 무관중 경기)는 별도로 구분하는 것도 좋습니다.
Q5. 크롤링이 어려운데 API만으로도 충분한가요?
A. 종목과 분석 범위에 따라 다릅니다.
TheSportsDB, API-Football 등 API는 구조화된 데이터 제공이 강점이며 학습용으로 충분히 활용 가능합니다.
하지만 일부 세부 지표(xG, 포메이션 등)는 크롤링(FBref, SofaScore 등)이 필요한 경우도 있습니다.
스포츠 예측모델 학습 데이터 수집 가이드에서는 크롤링과 API 병행을 추천합니다.
Q6. 경기 외적 요소(날씨, 휴식일 등)는 꼭 넣어야 하나요?
A. 단기 예측에서는 영향이 작을 수 있으나, 장기 분석에서는 중요할 수 있습니다.
예: 이동 거리, 휴식일 차이, 경기 요일(평일/주말), 시간대 등은 팀 컨디션과 연계되며, 특히 중립 경기나 국제 대회에서 효과가 큽니다.
Q7. 예측 모델을 구성할 때 어떤 알고리즘을 추천하나요?
A. 초기에는 다음을 추천합니다:
Logistic Regression: 기본적인 승/패 분류
Random Forest / XGBoost: 피처 해석력 + 정확도 우수
LightGBM: 속도와 성능의 균형
CatBoost: 범주형 자동 처리
고급 분석 시 시계열 예측(Pytorch LSTM, Prophet)도 고려할 수 있습니다.
Q8. 예측 정확도를 어떻게 평가하나요?
A. 가장 일반적인 방법은 **정확도(Accuracy)**입니다. 그러나 무승부나 저확률 경기가 많은 경우에는
Precision / Recall
F1 Score
ROC-AUC Curve
LogLoss
같은 다양한 지표로 함께 평가하는 것이 중요합니다.
#스포츠예측모델 #데이터수집가이드 #머신러닝스포츠 #스포츠데이터 #축구예측 #스포츠크롤링 #API축구데이터 #배당분석 #자동수집 #전처리코드
- 이전글토토 경기별 정적 데이터 분석법 마스터 가이드 25.06.23
- 다음글스포츠토토 픽 성능 추이 분석기 완전 설계 가이드 25.06.18
댓글목록
등록된 댓글이 없습니다.